Using Retrieval Augmented Generation to enhance general LLM

Generative LLMs are powerful tools for answering questions, writing documents, drafting emails, and even generating entire websites. However, they are quite limited in the data they have access to. Have you tried to query ChatGPT about current events, the company you work for, or even the newest restaurants? You’ll notice that ChatGPT can not answer these types of questions. LLMs only have access to information about things they were trained on, which limits their capabilities. Fortunately, this limitation can be avoided by using Retrieval Augmented Generation, or RAG for short.
RAG is a process where information that was not included in its training is provided to the LLM. To perform RAG, we analyze queries before they are passed to the LLM. We then retrieve any information needed to respond to the queries from a database. Once we have retrieved this information, we use it to augment the original query. We pass both the query and information to the LLM to get a response.
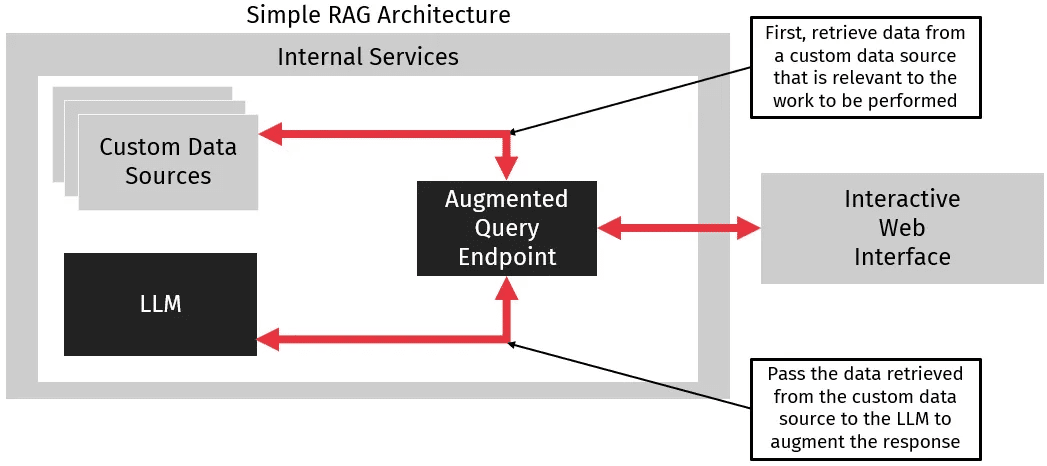
RAG is a practical choice when building a custom LLM implementation. It allows us to provide custom data without retraining, which has a few advantages. First, we can use an off-the-shelf LLM like ChatGPT since we don’t have to train a custom instance. This allows us to leverage world-class LLMs rather than trying to build, host, and secure our own instance. Second, we can provide up-to-date data without requiring a slow and expensive retraining process. Especially if we want close to real-time data, the effort required to keep a LLM up to date is simply impractical. Finally, RAG provides a relatively simple and easy way to create a custom GPT instance. It does this without prior machine learning experience and is a good starting point when creating a custom AI tool.
Understanding Retrieval Augmented Generation
What’s the key to understanding how Retrieval Augmented Generation adds information to an LLM without retraining? It’s in understanding how multiple messages can be provided to an LLM in order to answer a single query. Notably, most LLMs require a system message in addition to the user message to answer user queries.
System messages typically take the form of a specifier followed by a series of instructions. An example of a system message might be, “You are a friendly AI. Attempt to respond to queries in a polite and friendly manner. If you are unsure how to respond, tell the user you need more information”. In this example, the specifier is “You are a friendly AI.” It’s followed by two instructions telling the LLM how to respond. This example system message gives the LLM a lot of leeway regarding the data it can use in its response but restricts how those responses can be phrased. Similarly, we can use the system message to restrict what data the LLM is allowed to use in its responses.
We can take advantage of the system messages’ ability to restrict the LLMs functionality by providing custom information in the system message. We can then have the LLM use only this information when responding to queries, avoiding the risk of the LLM hallucinating information. This is how RAG works to answer queries, as shown in the diagram below.
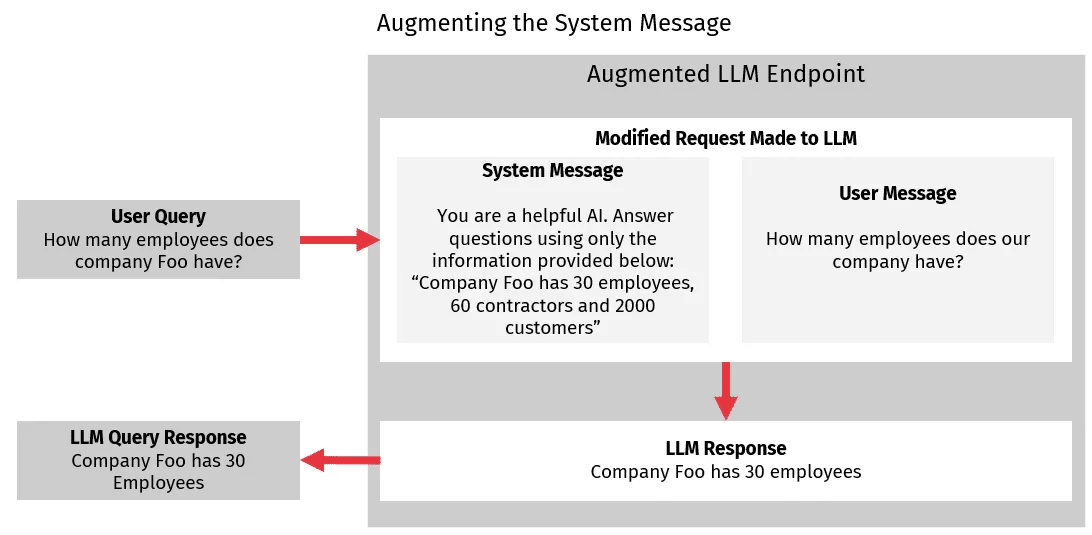
With RAG, when a user makes a query, we add the information needed to answer the query to the system message. We then instruct the LLM to use the information provided in the system message when answering the query. By doing this, the LLMs response can then contain information on which it was not trained but which we directly provided.
Retrieving The Information Needed For Augmented Generation
A key challenge with RAG is that responses will only be as good as the custom information provided to the system message. In the example in the diagram above, the system message contains the employee count information, but we can see that this initial approach generalizes poorly. It is impractical to provide any possible required information in the system message. Some type of search engine needs to be used to fetch the relevant data, which we can then append to the system message.
Fortunately, it is possible to create a search engine, given a set of documents, relatively easily. Apache Lucene provides a self-hosted solution to this problem, and Azure Cognitive Search or AWS OpenSearch both provide cloud-hosted solutions for quickly creating a search engine. All of these tools allow you to take a set of unstructured text documents, feed them into a store, run search queries against them, and then return a set of ranked search results. We can then take the pages from the search results and directly add their contents to the system message.
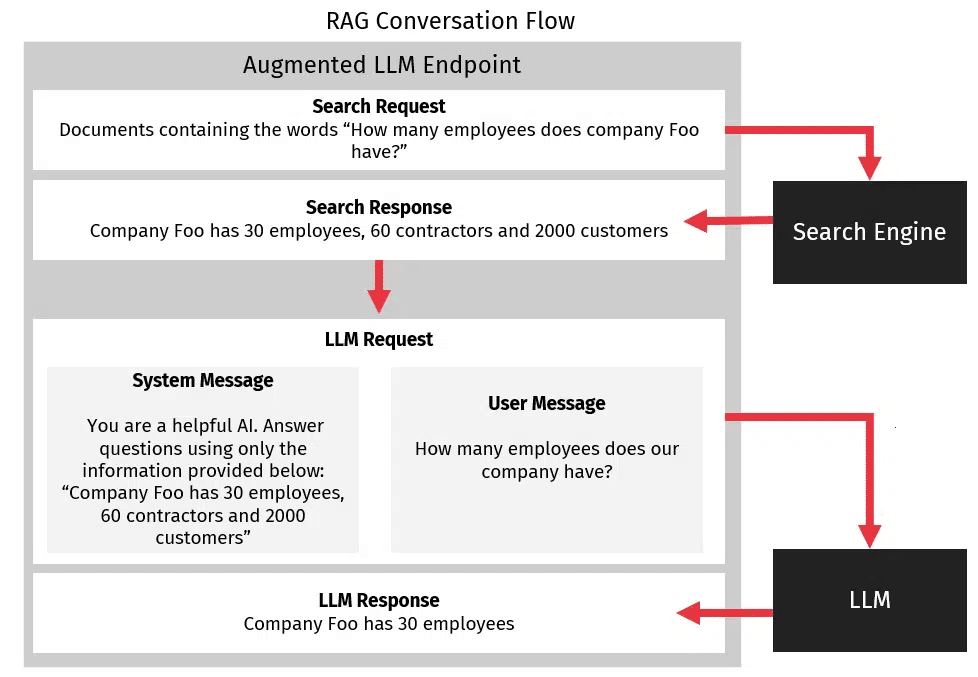
Retrieved information is provided to the LLM as unstructured text and is simply appended to the system message. For example, if we want to know how many employees our company has, we could fetch this information from our search engine, perhaps find an employee directory file, and then provide the file contents to our LLM as part of the system message. The LLM can then use this information to respond to the query.
When receiving search results from search engines, a general rule of thumb is to take the top 3-5 results and feed them into the LLM as part of the system message. Typically, the number of results you want to use is dependent on the quality of the documentation you are searching through. If you have a few large documents, then only a few results are required. On the other hand, if you have many small documents, then passing on more of the returned documentation will give better results. Note that minimizing the amount of data passed to the LLM will generally improve your results. Less data helps the LLM focus on the more important facts while also reducing network and request overhead, which by extension, helps to reduce costs.
Writing An Augmented System Message
The second key challenge in retrieval augmented generation is writing a system message that correctly answers queries. Notably, the system message needs to prevent the LLM from hallucinating incorrect information while also allowing it some leeway in the LLM’s responses.
When creating our system message, we should consider the use case for our LLM since we need to decide how much leeway our LLM will need. If the LLM will mostly be used to answer simple questions, for example, “How many employees does company Foo have?” then we can use a system message that prevents the LLM from being creative about its answers. For example, for this use case, we might want a system message like “You are a helpful AI assistant. You may only answer questions using the information provided below. If the answer is not contained in the information below, inform the user you do now know the answer”.
This sort of highly restricted system message is good at preventing an LLM from hallucinating but if we use the above system statement and ask the LLM a question like “Should I invest in company Foo?” the LLM will respond that it can not answer the question. This is because there is no information contained in the system message about investing, and the LLM is restricted to only answering using information contained in the system message.
To avoid this issue in the investment case, we could instead use a system message like “You are an AI specialized in investing. You have been given the following information about company Foo.” This instruction gives more leeway to the LLM to use its own information to determine the relevance of the additional information provided to it, but it also makes the LLM output less consistent when given direct questions.
An alternative to these two more focused messages is to use a system message like “You are a helpful AI assistant. You have been given the following information about company Foo to use with your own knowledge to help answer the following questions”. This system message provides more balance in allowing the LLM to use some of its own information with the information provided, but it can lead to challenges in some edge cases. Unfortunately, with more general messages, there is an increased likelihood of errors, and users should be aware that the system may generate incorrect responses in some cases.
Finally, we could choose a few of these system messages and have our users select one during their querying process. This adds more overhead to using the LLM, but it may be worth it to get better results.
In Conclusion
Generative LLMs are powerful tools, and as businesses and consumers look to leverage them, an important step will be integrating these tools with internal data. Retrieval augmented generation provides an easy and intuitive way to integrate an off-the-shelf LLM with external data sources, and the lightweight nature of an RAG solution makes it much more appealing than retraining an LLM. We can see that using both off-the-shelf search engine tools and an off-the-shelf LLM, we can quickly create a powerful question-answering service to help users leverage LLMs to the fullest.
Are you curious about building and enhancing your own LLM? Contact us for more information.
References
Azure Retrieval Augmented Generation Overview https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview