
We used retrieval augmented generation to implement a custom LLM endpoint for answering internal questions, improving documentation lookup speed, and creating company-specific documentation and marketing posts.
Our client
Undisclosed
The challenge
Our client wanted to encourage their employees to explore AI. Staff wanted to use ChatGPT to create marketing materials, answer frequently asked questions, and provide investor summaries. They were especially interested in creating more targeted documents, using ChatGPT to quickly change the tone, target audience, or language of various articles, ultimately allowing them to produce a wider variety of marketing content and respond to customer inquiries faster.
While ChatGPT performed well on some of these tasks, it often struggled in cases where internal corporate knowledge was needed. While summaries could be generated, they often required a significant amount of work to gather the information required by ChatGPT. Perhaps more concerning, specific questions would fail to be answered, or ChatGPT would hallucinate incorrect information, leading to confusion over information.
This inconsistency in responses led to extreme caution when using ChatGPT, which in turn led to productivity losses. In addition, management had security concerns about information being provided to ChatGPT, and it ending up becoming public.
How we helped
There were three primary goals for our solution:
- Allow staff to use an LLM to create documents without requiring significant work gathering the information needed.
- Ensure that documents and answers generated by the LLM do not include incorrect data.
- Address any security concerns around data leakage.
We decided the way forward was to create a custom LLM endpoint that could fetch internal data to address these three issues. We discussed different approaches and decided on retrieval augmented generation, or RAG, to add custom data to LLM queries.
Retrieval Augmented Generation
RAG is an approach to adding custom data to an LLM where instead of retraining the LLM on your custom data, you provide the data required to answer the query alongside the query itself. For example, if a user asks the LLM, “What does this widget do?” you might augment the query with information like “Widgets can be used for …” and then have the LLM answer the query using this provided information.
The information provided in RAG typically does not directly answer the question. Instead, we would typically provide something like the contents of the webpage or documentation where the answer resides along with the query. We then modify the query to something like “What does this widget do? Answer using the following information …” and then append the documentation to the end of the query.
RAG is a cost-effective approach to adding custom data to LLMs since it does not require an expensive retraining effort. In addition, it allows us to use an off-the-shelf LLM rather than trying to build and host an instance ourselves, and can easily be maintained and updated by updating the documentation provided with the queries. The challenge with RAG is in fetching the correct documentation to augment user queries, as well as rewriting the queries to use this data without breaking them.
Analyzing User Queries
As a first step, we gathered a list of queries users commonly made. Our goal was to understand what types of data users typically requested and what sorts of questions they often asked.
We built a small Python notebook using the Azure Machine Learning Studio and connected it to an Azure OpenAI resource, then tested out some of the example queries. Surprisingly, some of the queries were answerable without internal data, while others required significant internal knowledge.
We spent time breaking the example questions up into a set of categories depending on what kind of internal knowledge was needed. For example, marketing questions required some customer knowledge, while FAQ questions could almost exclusively be answered by information found in some reference materials. We similarly broke the questions up into question types in order to determine how much leeway to give the LLM when answering them. For example, when answering FAQ questions, the system needed to give short, direct answers taken straight from the text, but for investment summaries, the system needed to use judgment to determine what was most important.
Determining Architecture For The Custom LLM
Once we had an idea of what cases we needed to handle, we mapped out an initial architecture.
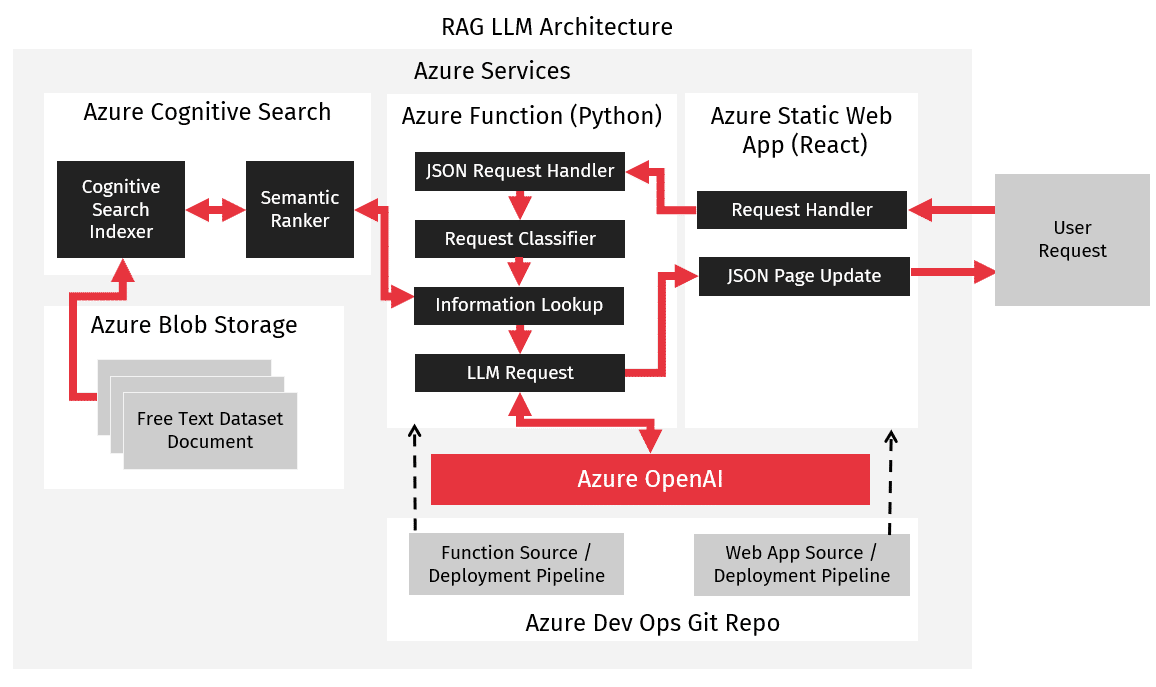
We determined that we could use Microsoft Azure to host a simple architecture composed of an Azure Static Web App, an Azure Function, and an Azure Cognitive Search database.
- Our static web app would provide an endpoint for users to enter queries, providing a site similar to the ChatGPT interface users were already familiar with.
- Our Azure Function would handle queries sent from the web app, and use our LLM to classify the queries to determine what data and query augmentation was needed.
- Our Azure Function would then query an Azure Cognitive Search database containing the client’s documentation to find the relevant documentation needed to answer the user query.
- The Azure Function would then send the augmented query and documentation to the LLM.
- Finally, the Azure Function would return the query result to the web app, where it would be displayed.
For our LLM, we chose to use Azure OpenAI to create a private endpoint. This was done to assuage security concerns while also allowing us to leverage a production-ready LLM rather than having to build and maintain our own instance.
Indexing The Data
Our first step was to gather and index the client’s data into the Azure Cognitive Search resource. We performed this step manually, scraping information from their intranet and then uploading it to the cognitive search resource. We enabled semantic ranking, and selected indexes based on what information was most likely to be looked up in queries.
Once we had the Azure Cognitive Search resource in place, we returned to our Machine Learning Studio notebook and re-ran our initially gathered example queries, augmenting them with data retrieved from the cognitive search. We verified that the correct data was retrieved for the different types of queries. Furthermore, we ensured that we could use the OpenAI LLM to classify our queries correctly so that query augmentation retrieved the right information and the augmented queries were correctly modified to allow the LLM leeway when answering queries as needed.
Creating the Custom LLM Endpoint
Next, we created our Azure Function. We used Python to implement our function since it has libraries for querying both Azure Cognitive Search and OpenAI resources. It also had the nice advantage of allowing us to reuse code from our previous testing with our Machine Learning Studio notebooks.
To store our code and deploy our function, we used Azure DevOps, a git repository that smoothly integrates with Azure resources. This greatly simplified the process of creating development and production functions for testing, as well as ensuring that we had a continuous development environment to keep things up to date.
Adding A Web Interface
Finally, we created a web interface using React, having our design team work directly with the client to ensure consistency with the rest of the client’s in-house tools. We once again used Azure DevOps to store and deploy the web app. Its direct integration with Azure means we could quickly deploy updates and manage the web application via code.
We then spent time working with the end users to iron out any issues they had. Notably, there were some concerns over how the interface illustrated that it was waiting for results from the LLM. Fortunately, these were easily resolved by adding some additional user feedback during the query process.
Results
Our custom LLM solution was able to safely and securely help users answer a variety of internal questions, making it easier for our client to create summaries of important documents and answer customer queries. We were also able to reduce the workload for their sales and marketing teams significantly.
Future Work
Now that the client has this custom LLM in place, they have reached out about doing the following:
- Automating Data Indexing
Currently, data indexing is a manual process, but automating this process is relatively straightforward, involving creating an automatic scraper and tracking when documents have been updated. - Integration With Other Tools
This implementation still requires the user to explicitly query for data or copy data to review into the web tool. In the future, we hope to integrate directly with some of the clients’ in-house tooling to make things more efficient. For example, the client discussed the possibility of integrating directly with their marketing email tool.
Please contact us for more information about this case study or how we can implement LLM technologies in your business.
Date
10/2023
Languages
Python
Javascript
Frameworks
OpenAI
Azure Document Search
React
Tools
Visual Studio Code
Azure ML Studio
Cloud
Azure
Discuss Your Project
Great things happen when good people connect. Leave us your details, and we’ll get back to you.
By sending the information in this form, you agree to have your personal data processed according to A-CX’s Privacy Policy and Cookie Policy to handle the request and respond to it.


